
David

En el mundo acelerado de DevOps, donde todo se mueve a mil por hora y la eficiencia es el nombre del juego, manejar los datos es como la columna vertebral de todo. Hoy en día, las empresas no solo necesitan guardar información, sino que deben hacerlo de forma escalable, segura y que esté siempre disponible. Y aquí es donde entra Amazon Web Services (AWS), cambiando por completo cómo vemos y usamos las bases de datos.
AWS nos tira una mano gigante con una colección brutal de servicios de bases de datos que ya vienen listos y administrados. Hay de todo, desde las bases de datos relacionales de toda la vida hasta las soluciones NoSQL más modernas. Lo mejor de esto es que AWS se encarga de toda la parte aburrida de la infraestructura, liberando a los equipos de DevOps para que puedan concentrarse en lo que de verdad importa: crear cosas nuevas y darle valor a sus usuarios.
AWS RDS
RDS significa servicio de bases de datos relacional que es gestionada por AWS
Si alguna vez has tenido que montar, configurar y mantener una base de datos relacional (como MySQL, PostgreSQL, Oracle, SQL Server o MariaDB) desde cero, sabes que puede ser un dolor de cabeza. Desde elegir el hardware adecuado, instalar el sistema operativo, configurar la base de datos, aplicar parches de seguridad, hacer copias de seguridad.
Ahí es donde entra Amazon Relational Database Service (RDS) para salvar el día. Imagina que es como tener un asistente personal súper inteligente que se encarga de todo ese trabajo pesado por ti. Con RDS, ya no tienes que preocuparte por la infraestructura subyacente. AWS se encarga de:
- Aprovisionamiento de hardware: Discos duros o la capacidad. Tú solo le dices a RDS qué tipo de base de datos quieres y con qué recursos, y él lo pone en marcha.
- Instalación y parches: RDS instala el motor de base de datos y se encarga de aplicar los parches de seguridad y las actualizaciones de versión de forma automática.
- Copias de seguridad y recuperación: RDS hace copias de seguridad automáticas de tu base de datos y de los registros de transacciones. Esto significa que puedes restaurar tu base de datos a cualquier punto en el tiempo, lo cual es bueno para la recuperación ante errores humanos. Además, puedes crear “snapshots” (instantáneas) manuales para propósitos específicos.
- Escalabilidad: Con RDS, puedes aumentar la capacidad de cómputo (cambiar a una instancia más grande) o el almacenamiento con solo unos clics, y en muchos casos, sin tiempo de inactividad.
- Monitoreo: RDS da herramientas para monitorear el rendimiento de tu base de datos, ver el uso de CPU, memoria, E/S, y detectar posibles cuellos de botella.
- Seguridad: Integrado con otras características de seguridad de AWS como VPC (para aislar tu base de datos en una red virtual privada), IAM (para controlar quién tiene acceso) y KMS (para cifrado de datos en reposo y en tránsito).
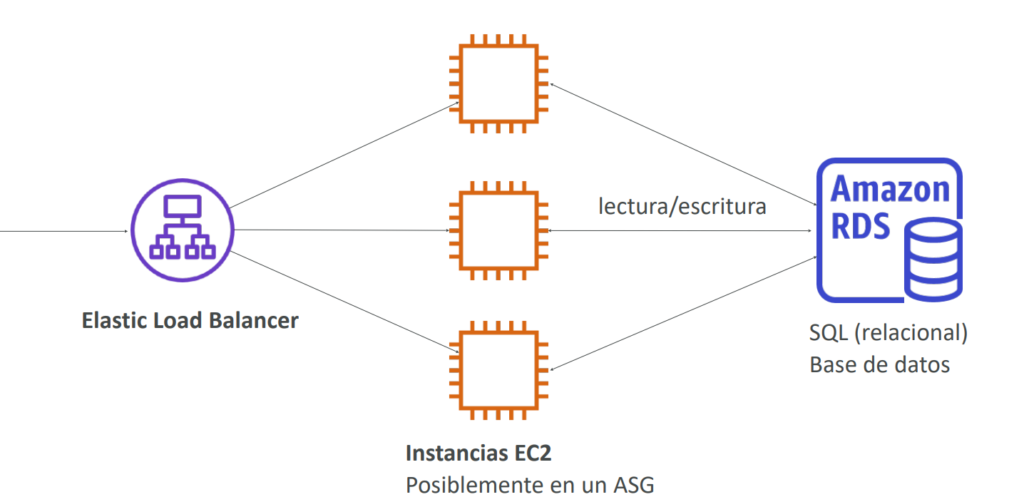
Crear RDS
1)Ingresar a AWS, Buscar RDS
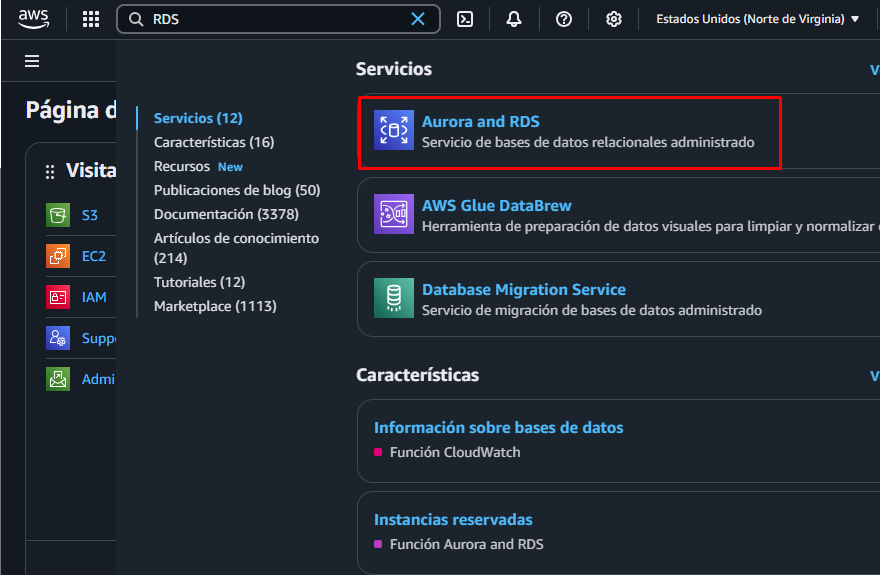
2)Click en Crear una base de datos
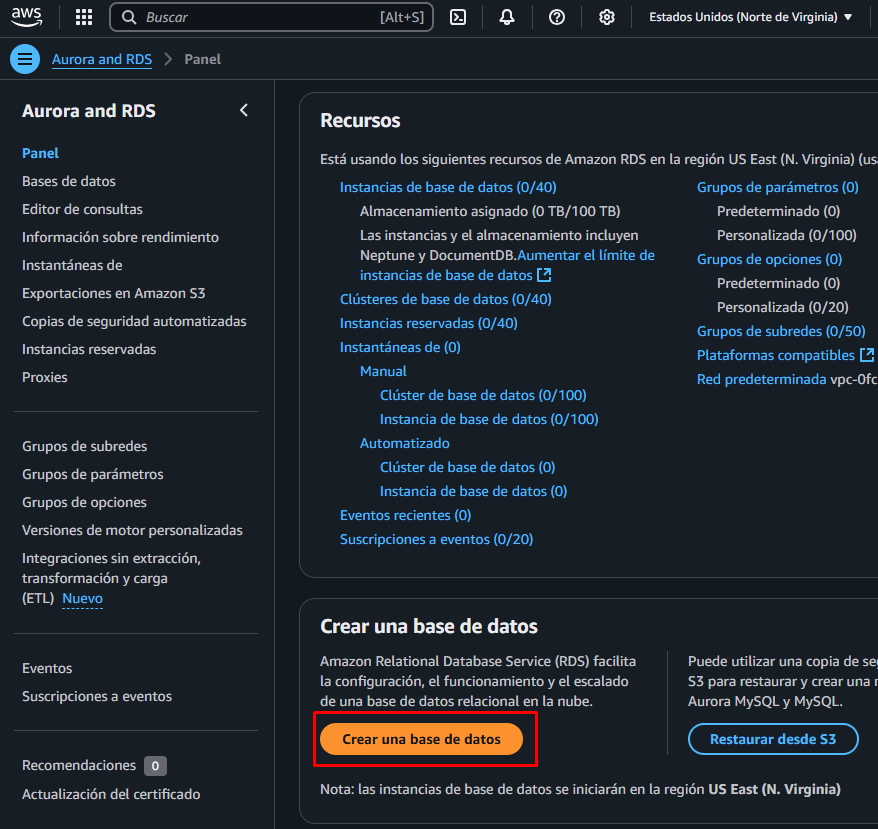
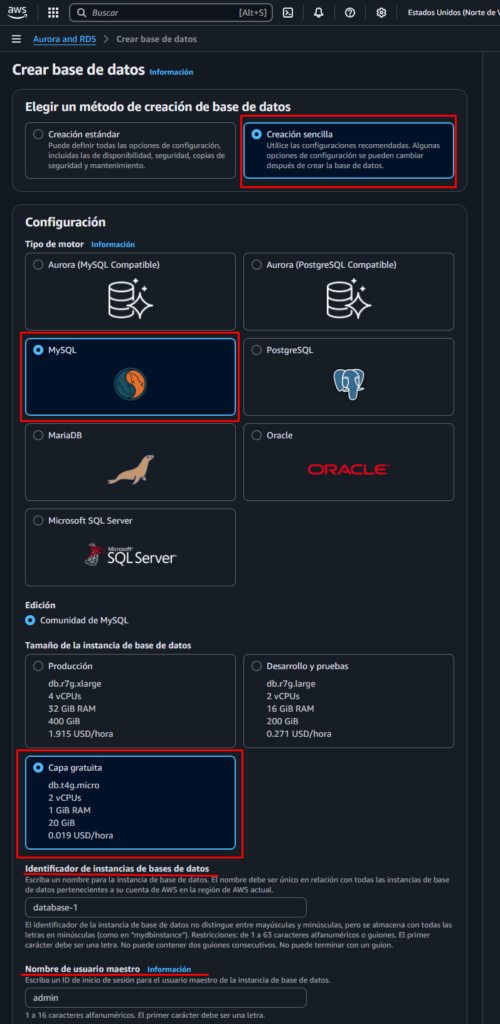
3)Metodo: seleccionar Creacion sencilla, > configuración seleccionar MySql, > seleccionar Capa gratuita, > modificar a elección Identificador de instancias de bases de datos, Nombre de usuario maestro, > crear base de datos
4)Validar la creación de la base de datos
Amazon Aurora

Si ya hemos hablado de Amazon RDS como el salvador para las bases de datos relacionales, es hora de presentar al “campeón de campeones” dentro de esa familia: Amazon Aurora. Imagina una base de datos que combine lo mejor de dos mundos: la compatibilidad y familiaridad de las bases de datos de código abierto (como MySQL y PostgreSQL), con la velocidad, disponibilidad y escalabilidad de las bases de datos comerciales de alta gama. Eso es precisamente lo que Aurora te ofrece.
Desarrollada por AWS desde cero para la nube, Aurora no es solo otra versión de MySQL o PostgreSQL. Es una base de datos relacional completamente optimizada para la nube, diseñada para ofrecer un rendimiento y una confiabilidad excepcionales. AWS afirma que Aurora puede ser hasta 5 veces más rápida que MySQL estándar y hasta 3 veces más rápida que PostgreSQL estándar, todo mientras mantiene la compatibilidad con sus respectivos motores. Esto significa que puedes migrar tus aplicaciones existentes a Aurora con mínimos cambios, pero disfrutando de un salto gigantesco en rendimiento.
Pero Aurora no solo se trata de velocidad. Su arquitectura única desacopla el almacenamiento del procesamiento, permitiéndole escalar de forma independiente y ofrecer una resiliencia y durabilidad. Con funcionalidades como su almacenamiento auto-reparable, réplicas de lectura de baja latencia y conmutación por error automática y casi instantánea, Aurora está diseñada para mantener tus datos seguros y accesibles incluso frente a fallos.
Amazon Elastic cache

Amazon ElastiCache no es una base de datos en sí misma, sino un compañero invaluable para mejorar el rendimiento de tus aplicaciones y bases de datos.
Si tu aplicación es un restaurante. Tu base de datos es la cocina, donde se preparan todos los platos (se procesan los datos). Si cada vez que un cliente pide un plato (una consulta), el chef tiene que ir a buscar todos los ingredientes desde cero, la fila se hará larguísima y la gente se irá.
Aquí es donde entra Amazon ElastiCache, que sería como tener una despensa de ingredientes “listos para usar” justo al lado del chef, o un camarero con una memoria prodigiosa que ya sabe lo que la mayoría de los clientes pide y lo trae de inmediato.
ElastiCache es un servicio de caché en memoria completamente administrado por AWS. Su propósito principal es acelerar el rendimiento de tus aplicaciones al reducir la latencia de acceso a los datos y la carga sobre tus bases de datos o servicios de backend. ¿Cómo lo hace? Almacenando en la memoria (RAM) los datos que se acceden con más frecuencia. Acceder a datos desde la RAM es miles de veces más rápido que hacerlo desde un disco duro o incluso desde una base de datos optimizada.
Casos de Uso Típicos:
- Sitios web y aplicaciones móviles de alto tráfico: Para servir contenido dinámico o sesiones de usuario rápidamente.
- APIs: Caché de respuestas de API para reducir la carga en los servicios de backend.
- Sistemas de recomendación: Almacenar recomendaciones personalizadas para un acceso instantáneo.
Dynamo DB
Si tu aplicación necesita manejar cantidades masivas de datos y requiere una velocidad de acceso constante, con latencias de milisegundos.
A diferencia de las bases de datos relacionales tradicionales (como las que maneja RDS y Aurora, que usan tablas y relaciones), DynamoDB es una base de datos NoSQL de tipo clave-valor y de documentos. Esto significa que es increíblemente flexible con la estructura de tus datos y está diseñada para manejar cargas de trabajo enormes a una alta velocidad.
DynamoDB DAX
Ya hemos visto que Amazon DynamoDB es increíblemente rápido y escalable. Pero, ¿qué pasa si tu aplicación es tan exigente que necesitas lecturas aún más rápidas, con latencias de microsegundos en lugar de milisegundos.
DAX es un servicio de caché en memoria completamente administrado y optimizado para DynamoDB. Es como poner un turbo especial directamente sobre tu tabla de DynamoDB para acelerar las lecturas, especialmente las que se repiten mucho.
¿Cómo funciona DAX?
Piénsalo así:
- Tu aplicación, en lugar de hablar directamente con DynamoDB para cada lectura, primero le pregunta a DAX.
- Si DAX ya tiene el dato en su memoria (un “cache hit”), te lo entrega instantáneamente (en microsegundos).
- Si DAX no tiene el dato (un “cache miss”), entonces DAX va y lo busca en DynamoDB por ti, lo guarda en su caché para futuras peticiones, y luego te lo devuelve.
Tablas Globales de DynamoDB
Si tu aplicación no solo necesita ser rápida y escalable, sino que además tiene que estar disponible para usuarios en diferentes partes del mundo y ser resistente a fallos regionales completos.
Una Tabla Global es una colección de una o más tablas de DynamoDB idénticas que se encuentran en diferentes regiones de AWS.
Amazon RedShift

Imagina que tienes una cantidad brutal de datos – hablamos de terabytes, incluso petabytes – que vienen de tus aplicaciones, de tus registros, de sensores, de ventas, y necesitas sacarles jugo. No quieres solo almacenar esa información; quieres analizarla, encontrar patrones, generar informes complejos, entender el comportamiento de tus usuarios o predecir tendencias.
Aquí es donde brilla Amazon Redshift. No es una base de datos transaccional (OLTP) como las que conoces para tu día a día, sino un data warehouse (almacén de datos) diseñado específicamente para el análisis masivo de datos (OLAP). Es una base de datos orientada a columnas y utiliza una arquitectura de procesamiento masivamente paralelo (MPP).
¿Cuándo usar Redshift?
Redshift es la herramienta ideal para:
- Business Intelligence y Reporting: Generar informes de ventas, rendimiento, comportamiento del cliente.
- Análisis de Big Data: Cuando necesitas analizar datos masivos para identificar tendencias, patrones o anomalías.
- Data Lakes: Como el motor de consulta para tu Data Lake en S3, permitiendo a los analistas consultar directamente los datos sin tener que moverlos.
- Consolidación de Datos: Centralizar datos de múltiples fuentes para un análisis unificado.

David Guzmán López
Ingeniero Electrónico
Electronic Engineer | DevOps Engineer | SRE | Cloud Engineer | Infrastructure Engineer